
Organizations rely on software and external services to protect computing environments, monitor activity, and safeguard sensitive data. These solutions combine automated tools, operational processes, and human oversight to detect anomalous behavior, control who can access systems, and reduce exposure to known vulnerabilities. They typically operate across endpoints, networks, cloud platforms, and applications, and they may integrate with logging, configuration management, and business processes to provide ongoing protection and visibility.
Key functional areas include continuous monitoring, identity and access controls, vulnerability discovery, and structured response to security incidents. Software components often provide telemetry collection and analytics while services can include managed monitoring, consulting, or incident handling support. Implementations vary by organization size and risk profile; selections commonly balance coverage, integration complexity, and operational workload rather than relying on a single product or metric.

Monitoring and detection capabilities often form the operational backbone of cybersecurity programs. Telemetry sources such as endpoint agents, network flow records, cloud audit logs, and application traces can feed analytics engines that may flag suspicious sequences or patterns. Detection techniques can include signature-based matching, anomaly detection, and correlation rules that combine multiple data points. Monitoring systems typically generate many signals; organizations often apply tuning, prioritization, and triage processes so that security teams can address higher-risk findings first.
Vulnerability assessment and management typically involve scanning, inventory, and prioritization. Scanners may identify missing patches, misconfigurations, and exposed services, while asset inventories help map which findings affect critical systems. Prioritization commonly factors in exploitability, exposure, and business impact so that remediation resources focus on higher-consequence items. Assessment cycles can be regular (weekly or monthly) and may be supplemented by periodic third-party penetration tests to surface issues that automated scans may not detect.
Identity management and access control functions aim to reduce the risk of unauthorized access. Measures include centralized credential stores, role-based access controls, session logging, and multifactor authentication. Access reviews and least-privilege models often form procedural complements to technical controls, and organizations may use privileged access management tools to govern elevated accounts. These controls typically interact with other components such as directory services, single sign-on, and user provisioning systems for coherent enforcement.
Incident response and recovery capabilities are a core function of many cybersecurity programs. Playbooks define detection-to-remediation steps, roles, and communications protocols; forensic capabilities preserve evidence for analysis; and containment strategies limit spread while remediation restores normal operations. Some organizations maintain in-house incident response teams while others engage external responders or retain managed detection and response services to support faster containment. Post-incident reviews commonly inform control adjustments and future planning.
In summary, effective cybersecurity stacks combine detection, preventive controls, asset knowledge, and response planning. Different tools and services may be integrated to provide coverage across endpoints, identities, and networks, and operational practices such as prioritization and periodic testing often influence overall resilience. The next sections examine practical components and considerations in more detail.

Software and services in this domain fulfill different roles: preventive controls aim to reduce exposure, detective controls identify anomalous activity, and corrective processes restore systems after an event. Preventive examples include patch management and configuration hardening tools; detective examples include EDR and SIEM; corrective elements include backup and orchestration tools for remediation. Service models may be advisory, managed, or on-demand assistance for incident handling. When assessing categories, organizations often consider how components interoperate, which telemetry they share, and the operational burden of alerts and maintenance.
Coverage decisions often reflect an inventory-driven approach: critical assets typically receive greater monitoring and stricter access controls. Many organizations report handling hundreds to thousands of security events per day across combined telemetry sources, which underscores the need for correlation and prioritization. Integration patterns commonly include forwarding logs to centralized analytics, feeding identity events into access reviews, and using vulnerability data to focus patching. These practices can reduce noise and align technical controls with organizational risk tolerance.
Service delivery choices — in-house versus managed — tend to depend on available staff and required 24/7 coverage. Managed detection and response services may provide continuous monitoring and escalation pathways, while internal teams maintain intimate system knowledge and direct control over containment. Hybrid approaches are common: in-house teams handle tactical tasks and governance while external services address capacity or specialized forensic needs. Contractual clarity about responsibilities and data handling often influences the effectiveness of these arrangements.
Operational considerations include agent coverage, false-positive rates, update cadence, and platform compatibility. Agents can provide rich telemetry but may affect endpoint performance; cloud-native telemetry may require different collectors and permissions. False positives can consume analyst time, so tuning rules and leveraging threat intelligence to contextualize alerts often improves efficiency. These considerations may inform procurement and deployment strategies, with phased rollouts and pilot programs used to validate fit before broader adoption.

Detection methods may combine signature databases, heuristic rules, behavioral analytics, and machine-assisted correlation. Signature-based detection can quickly identify known malicious indicators, while behavioral approaches may surface novel or stealthy activity by detecting deviations from established baselines. Correlation engines commonly link events across hosts, accounts, and network segments to reveal multi-stage patterns. Effective detection strategies often employ layered techniques so that indicators missed by one method may be captured by another.
Vulnerability assessment typically includes automated scanning, asset discovery, and contextual scoring. Scanners identify missing updates, insecure configurations, and exposed services; asset discovery helps ensure that unknown systems do not evade assessment. Contextual scoring may factor in exploit availability, asset criticality, and compensating controls to help prioritize remediation. Organizations frequently integrate scan outputs into ticketing or patch management systems to close the loop and track remediation progress over time.
Threat intelligence can augment detection and assessment by providing indicators of compromise, exploit trends, and attacker techniques. When applied cautiously, intelligence feeds may enrich correlation rules and provide context for prioritization; however, large volumes of threat indicators can increase noise if not filtered for relevance. Many organizations apply reputation scoring or contextual filters so that intelligence is actionable and aligns with known assets and business processes rather than generating broad, unfocused alerts.
Considerations for these functions include data retention, privacy, and resource allocation. Retaining sufficient telemetry supports historical analysis but increases storage needs and potential privacy exposure, so retention policies often balance investigative value against operational cost and legal considerations. Sampling strategies, tiered storage, and data minimization are commonly employed. Teams often document expected handling for sensitive logs and establish review cycles to ensure assessment processes remain aligned with evolving infrastructure.
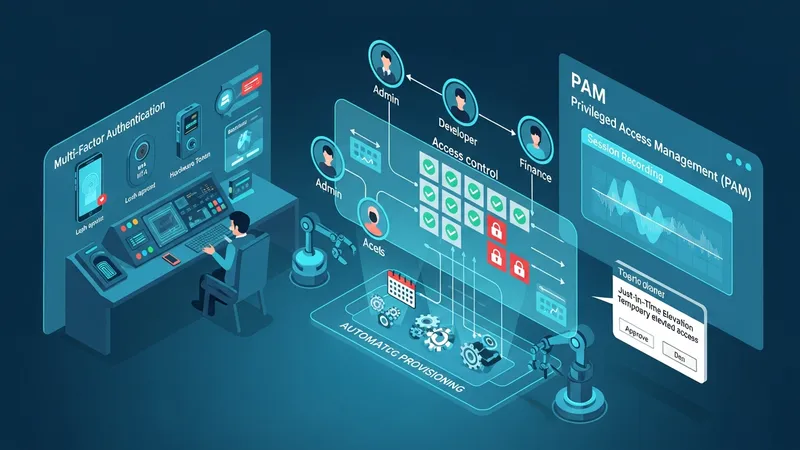
Identity management systems centralize user lifecycle processes such as onboarding, role assignment, and deprovisioning. These systems often integrate with authentication mechanisms and may support single sign-on and federation for cross-domain access. Access control models such as role-based access control (RBAC) or attribute-based approaches can help align user privileges with responsibilities. Periodic access reviews and automated provisioning workflows may reduce stale privileges and help maintain least-privilege postures.
Multifactor authentication (MFA) and privileged access management (PAM) are common technical controls for reducing account compromise risk. MFA typically combines something a user knows with something they have or are, which can reduce credential-based attacks. PAM solutions may place elevated accounts in managed sessions, log activity, and require just-in-time elevation in some implementations. These controls often integrate with audit and monitoring systems so that privileged actions are visible and reviewable.
Data protection measures include encryption at rest and in transit, tokenization, and data loss prevention (DLP) controls. Encryption may be applied at storage, database, or application layers and is often complemented by key management services. DLP tools may monitor and block exfiltration paths or apply policy-based controls for sensitive content. Data classification programs often inform which protections are applied to particular information types and where stricter controls are warranted.
Practical considerations include managing credential lifecycle, balancing usability with control, and documenting data handling procedures. Overly restrictive authentication or access flows may drive users to work around controls, while lax practices increase exposure; striking a balance often requires governance, awareness training, and periodic review. Organizations may adopt phased deployments for identity controls to smooth user experience impacts and to validate integration with existing business systems.

Incident response frameworks define detection, containment, eradication, and recovery activities and often include communication plans and evidence preservation steps. Playbooks may be tailored by incident type—malware, credential compromise, data loss—and should align with legal and regulatory obligations. Post-incident reviews frequently identify process gaps, instrumentation needs, and training topics; such reviews may drive adjustments to monitoring rules, detection thresholds, or system hardening activities.
Service delivery models vary from fully in-house operations to fully managed offerings. Managed services can provide extended hours coverage, threat hunting, or specialized forensics support, while internal teams provide direct access to environments and institutional knowledge. Hybrid arrangements often pair an internal security operations center with external advisory or surge-response support. Contractual clarity about roles, escalation paths, and data handling is a key consideration when engaging external providers.
Evaluation of tools and services commonly uses operational metrics such as mean time to detect, mean time to contain, false positive rates, and coverage of critical assets. These metrics are typically interpreted as trends rather than absolute performance guarantees and used to guide investments and process changes. Pilot deployments, reference architectures, and technical interoperability testing may help verify that a product or service fits operational workflows before broader adoption.
When planning for ongoing improvement, organizations may adopt continuous testing and measurement practices, such as simulated exercises and tabletop reviews, to validate response readiness. Regularly scheduled assessments, combined with lessons from actual incidents and evolving threat information, can inform updates to configurations, monitoring rules, and staff training. These iterative cycles typically increase resilience over time without implying any single tool or service is sufficient on its own.